

Subscribe to our research releases
Stay in touch with our latest insights, news and events.
Robust Intraday Volume Estimation for Schedule-Based Algorithms Using Machine Learning and Market Microstructure Insights

Abstract
Accurately forecasting intraday trading volume is crucial for optimizing commonly used execution strategies, including VWAP, POV, and IS algorithms. This paper presents a comprehensive methodology to predict minute-by-minute volume distributions for a vast universe of U.S. equities. The approach to estimating schedules for such algorithms presented here can be easily replicated to suit various markets and asset classes.
While the aggregate intraday volume distribution for the entire US equity market can be quite robust, the intraday volume patterns vary dramatically across stocks. Predicting intraday volume patterns using a historical intraday volume profile for each stock is robust only for about 1,500 highly liquid stocks. The remaining stocks must be clustered into groups of stocks with similar intraday volume patterns. In the approach shared here, we utilize machine learning to estimate intraday volume patterns to enhance the performance of algorithmic execution strategies. We find that for the most liquid stocks–even though they do not need to be clustered–the predictions are only robust in 10-minute bins; they are not robust at the minute-by-minute level. For these stocks, we introduce interpolation techniques, differentiated by their market structure differences, to estimate a robust minute-by-minute intraday volume pattern.
Introduction
Accurately forecasting expected volume plays a fundamental role in the performance of execution algorithms, serving as a key input that guides trading decisions. A well-designed schedule enables an algorithm to execute the order in a way that aligns with the security's natural liquidity dynamics, ultimately reducing market impact and trading costs.
Schedules determine how child orders are distributed across trading hours. Widely utilized trading strategies like VWAP (Volume Weighted Average Price), Close (trading into the close), and Implementation Shortfall (IS) rely on schedules to execute orders accounting for stocks’ expected volume across a specified time window. For instance, consider a VWAP order for a European ADR trading in the US Equity market which is more “front-loaded” due to the overlapping European and American trading hours. If the volume profile used by the algorithm is incorrect, it will execute less (than the market volume) during the European hours and more after the European markets are closed (than the market volume). This will both create higher market impact as well as higher variance from the VWAP price of the day.
While achieving perfect accuracy in matching each stock’s volume profile is unrealistic due to the noise in the volume profile itself, even incremental improvements in forecasting can enhance performance, leading to more effective execution and better cost outcomes. In this paper, we explain the theory and development of a new methodology using empirical volume distributions to predict minute-by-minute volume more accurately. This analysis covers the universe of roughly 8,300 stocks in the U.S. equity market. The sample period is Q4 2024.
To effectively capture the intraday volume patterns of this universe of stocks, we propose a hybrid approach, combining machine learning techniques with deep market microstructure understanding. In this analysis, we exclude auction volumes and focus only on estimating intraday minute-by-minute volume distribution during continuous trading from 9:30 am to 4:00 pm ET.
Considerations for Effective Volume Profile Creation
At first glance, it may appear the ideal approach to creating volume profiles includes a unique profile for each individual stock being traded. However, in practice, this is not an optimal solution. For less-liquid stocks, daily volume distributions can be highly variable, making stock-specific profiles highly unreliable. While general trends—such as increased trading activity at the market open and close—may persist, day-to-day fluctuations in limited volume can introduce significant noise, reducing the predictive value of these profiles.
As a result, a key research question is to determine which stocks can support stock-specific profiles and which cannot. For those stocks where a dedicated profile is not practical, an alternative approach must be considered. Identifying an appropriate method for grouping stocks or applying alternative volume estimation techniques is essential in these cases.
In the following sections, we describe an approach that balances the need for granularity with the stability of observed trading volume patterns, providing a practical and effective methodology for volume estimation.
Defining Liquidity-Based Groups for Volume Profiling
Not all stocks exhibit the same characteristics, and as a result, volume profiles cannot be created and applied uniformly across all securities.
Highly Liquid stocks tend to demonstrate stable and predictable volume patterns, making it feasible to generate stock-specific profiles. These profiles exhibit minimal noise over time, providing a reliable foundation for execution strategies.
In contrast, Low Liquidity stocks often exhibit instability and fluctuations in their daily trading volume as described above. If a stock’s trading activity fluctuates unpredictably from one day to the next, its volume profile lacks consistent structure and predictive capability for future trading volume. But execution algorithms still require a structured framework to operate effectively. The best approximation in these scenarios is to construct an average volume profile that captures general trends without overfitting to daily fluctuations–leaving the open question of how best to do that.
These two distinct categories do not fully capture the entire universe of stocks. Some stocks are neither Highly Liquid nor Low Liquidity, requiring a thoughtful approach of their own appropriate for their behavior and reliability. These stocks fall into an intermediate category where their volume distributions may not be sufficiently robust for stock-specific profiles, yet they exhibit more structure than Low Liquidity stocks. As a result, they require additional consideration in establishing a reliable and effective volume distribution.
Effective classification requires analysis of historical volume distributions and assessment of noise around each distribution. In the following sections, we detail group formation and how volume profiles are constructed and applied within each group.
Highly Liquid Stocks
We define Highly Liquid Stocks as those that exhibit a consistent and robust intraday volume distribution at the 10-minute interval level, with stock price greater than $1 and an average daily notional traded value of at least $100,000. To further ensure stability, we apply a criterion based on the Coefficient of Variation (CV)—a metric that measures relative variability as the ratio of standard deviation of the distribution to its mean. A stock is classified as stable if the CV for each of its 10-minute bins over a 30-day period is less than or equal to 0.25. By definition, this threshold provides at least 95% confidence that the average volume in any given bin for a new month will remain within ±50% of the corresponding bin’s value from the current month.
Stocks meeting these conditions are good candidates for individualized intraday volume curves, estimated in 10-minute intervals. Approximately 1,500 stocks in our universe satisfy these criteria. Figure 1 below shows the 30-day average fraction of intraday volume in each bin along with the 95% confidence intervals for the 5 least liquid stocks (by ADV) that are considered “Highly Liquid” as per our classification.

Figure 1: Fraction of volume traded for 5 least liquid within the Highly Liquid Group (10-min bins) along with 95% confidence interval.
In the first step of volume distribution generation, we use 10-minute bins to balance granularity with stability in volume estimation. While 1-minute data provides greater detail, it is highly sensitive to short-term fluctuations and exchange-specific auction effects, particularly near market close. By constructing volume profiles at the 10-minute level, we achieve a more stable and representative trading pattern while still preserving stock-specific characteristics. This approach minimizes noise and enhances reliability in execution strategies. Of course, a thoughtful methodology for shifting from 10-minute bins to 1-minute bins is also required.
Once the 30-day average 10-minute volume distribution is developed for each stock in this group, we incorporate the granularity of 1-minute distributions via interpolation. However, we do not interpolate based on the average behavior across all stocks. It is critical in creating effective profiles to account for exchange-specific variations in trading behavior, particularly those driven by the auction mechanics of NYSE and NASDAQ, as well as the unique behaviors of ETFs.
To accurately capture these microstructure effects, each stock is categorized into one of the following four groups:
- Common stocks listed on NYSE (XNYS)
- Common stocks listed on NASDAQ (XNAS)
- Common stocks listed on other exchanges (Other)
- Exchange-traded funds (ETF)
As shown in Figure 2, the market-specific effects are most pronounced during the 3:50 to 4:00 pm window, where significant volume spikes occur due to imbalance feed dissemination and auction-driven trading activity. Figure 2 also illustrates just how distinct the behaviors of each group appear.

Figure 2: Exchange- and auction-specific intraday volume distribution (1-min bin) by group for Highly Liquid stocks.
Once classified, we derive 1-minute volume distributions for each stock in the Highly Liquid group via the following steps:
- Calculate the average 1-minute volume distribution for the stock's assigned group.
- Interpolate the group-level 1-minute distribution to align with the stock’s individualized 10-minute volume profile.
Moderately Liquid Stocks
Unlike Highly Liquid Stocks, Moderately Liquid Stocks do not exhibit a stable intraday volume profile and therefore require additional processing to derive reliable volume estimates. They are characterized by weaker or less consistent volume distribution patterns at the 10-minute bin level. Individually these stocks fail the robustness criterion of having a coefficient of variation (CV) less than 0.25 applied to highly liquid stocks, but they meet the criteria of having a stock price greater than $1 and an average daily notional value of at least $100,000. Approximately 6,000 stocks fall into this category.
To establish a stable volume distribution for these stocks, we apply k-means clustering–a machine learning technique that groups items based on similarity in their characteristics. Here, the characteristics being clustered are the portions of total volume traded in each bin. The clustering process utilizes 1-minute binned volume data from October 2024 to group stocks with similar profiles, creating a single, more robust group profile to be shared by group members. Clustering these stocks at the 1-minute bin level–and allowing more than one cluster–should naturally account for any necessary market microstructure differences. We evaluate cluster counts ranging from 1 to 15, selecting the optimal number by maximizing separation between clusters while ensuring the robustness of the profile created for each group. A cluster is deemed to be robust if each 1-minute bin has a coefficient of variation (CV) less than 0.25.
Selecting the Optimal Number of Clusters
The table below presents key metrics used to determine the optimal number of clusters (k) for classifying Moderately Liquid Stocks:
- Number of Clusters (k): The total number of clusters considered in the analysis.
- Count of Noisy Clusters: The number of clusters where at least one bin has a CV ≥ 0.25, indicating instability in the volume distribution.
- % of Unstable Bins in Noisy Clusters: The proportion of bins classified as unstable within the identified noisy clusters.
- Separation Value (%): Calculated as the maximum difference in cumulative volume distribution between all the clusters. A higher separation value indicates greater distinction between clusters. For example, a separation value of 10% indicates that, at its most divergent point, the maximum deviation between cumulative distributions of all clusters differs from another by 10 percentage points.

Table 1: K-means clustering results including number of clusters and their characteristics.
From Table 1 above, we observe that as the number of clusters increases, separation values improve, indicating stronger differentiation between clusters. However, beyond k = 7, noisy clusters begin to emerge, and their prevalence increases with additional clusters. Given this trade-off, we determine that 7 clusters provide the best balance between cluster separation and robustness for modeling the volume distributions of Moderately Liquid Stocks. More detailed analysis of the resulting clusters, including their shape and other characteristics, is presented in the Appendix.
To further assess the reliability of our clustering approach, we visually compared the aggregate 1-minute binned volume distributions of each cluster created from the training set (October). Figure 3 depicts this, illustrating the difference between the maximum and minimum estimated daily volume fractions (accumulated within 10-minute bins where differences are more pronounced).

Figure 3: Difference between maximum and minimum estimated daily volume fractions across clusters, referred to as “maximum separation”, for training data (October).
Testing Clusters on Out-of-Sample Data
Having identified 7 clusters as the optimal grouping for moderately liquid stocks, we now evaluate their performance on out-of-sample data from November and December 2024. While the initial clustering process was conducted using October 2024 data, this validation step assesses whether the volume distributions remain stable over time and applicable to unseen data.
Below, we present the 1-minute binned volume distributions for each of the clusters, comparing the training period (October) with the out-of-sample periods (November and December). This analysis helps determine whether the derived cluster structure generalizes well beyond the initial dataset, ensuring its reliability for execution algorithms.
The intraday volume fraction plots for all the clusters demonstrate the stability of our clustering approach across different months. The volume distributions for October (training set), November, and December (test sets) align closely, indicating strong consistency in volume patterns. The lack of significant deviations suggests that the seven clustered profiles predict unseen data well. The consistency of the cluster analysis results, as illustrated in Figure 4a-g below, suggests that execution algorithms relying on the resulting volume distributions can expect consistent performance over time without needing to redefine the clusters more frequently than quarterly or even annually.



Figure 4a-g: Intraday volume fraction for each cluster, comparing test and out-of-sample performance.
Low Liquidity Stocks
We define Low Liquidity Stocks to be those with share prices below $1 and/or an average daily trading notional under $100,000. This category includes approximately 800 stocks, characterized by high illiquidity and sparse trading data. Their lack of sufficient volume requires a more aggregated approach to establish meaningful volume distributions at the 1-minute bin level.
To address this, all stocks in this category are grouped together rather than clustered individually, as their limited trading activity does not support distinct volume profiles. A single group-wide distribution is then derived, using notional-weighted volume rather than absolute trade volume alone. Weighting by notional value ensures that the distribution better reflects the overall market impact of trading these illiquid stocks, rather than being skewed by a few small trades. By adopting this approach, we mitigate potential market impact while providing a more stable and effective execution strategy. In Figure 5 below, we present the month-over-month distribution trends for this category.

Figure 5: Model validation for Low Liquidity stocks, illustrating similarity of generated profile and realized out-of-sample volume.
Profile Performance
To assess the effectiveness of the new methodology in generating our volume curves, we conducted a performance evaluation, comparing this new method’s effectiveness to that of our previous approach. Effectiveness is measured via comparing each method’s predicted volume distribution to the realized volume distribution for the same day. The evaluation was performed on four test days (Nov 1, Nov 16, Dec 1, and Dec 16, 2024), ensuring a 15-day gap between each test date. For each stock in the Highly and Moderately Liquid groups on each test day, volume estimates were generated using both the old and new methodologies, and performance was measured using two key metrics.
Metric 1: Separation Value
This measures the maximum distance between the cumulative distributions of estimated and actual volume curves. It indicates the largest possible discrepancy in the two intraday cumulative volume distributions being compared, which is particularly relevant for full-day VWAP strategies.
The results shown in Table 2 below indicate that the new methodology for generating volume profiles reduces the average error for Highly Liquid Stocks by 20% and the median error by 13% when compared to our previous approach. For Moderately Liquid Stocks, the average error is reduced by 6% and the median error is reduced by 10%.

Table 2: Reduction in error (Separation Value measure) of new methodology versus previous approach.
The charts below compare the error of the new and previous methodologies using the Separation Value metric across Highly Liquid and Moderately Liquid stock groups. The X-axis represents the separation value, and the Y-axis shows the frequency of occurrences.

Figure 6a & 6b: Histogram of separation values between estimated and actual volume distributions across all four test dates for Highly Liquid (a) & Moderately Liquid (b) stock groups.
Metric 2: Euclidean Distance
This measures the average Root Mean Squared Error (RMSE) per 1-minute bin, computed as:
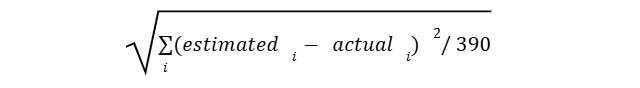
Where, i runs from 1 to 390 (representing the 390 one-minute intervals in a trading day). For this measure, a lower value indicates a better fit between the estimated volume and the actual volume.
The results shown in Table 3 below indicate that the new methodology for generating volume profiles reduces the average error for Highly Liquid Stocks by 5% and the median error by 9% when compared to our previous approach. For Moderately Liquid Stocks, both average and median error is reduced by 1%.

Table 3: Reduction in error (Euclidean distance metric) of new methodology versus previous approach.
The charts below compare the error of the new and previous methodologies using the Euclidean Distance metric across Highly Liquid and Moderately Liquid stock groups. The X-axis represents the Euclidean distance measure , and the Y-axis shows the frequency of occurrences.

Figure 7a & 7b: Histogram of Euclidean Distance values between estimated and actual volume distributions across all four test dates for the Highly Liquid (a) & Moderately Liquid (b) stock groups.
Overall, the new methodology demonstrates notable improvements for Highly and Moderately Liquid stocks by both measures, with reductions in both average and median errors across both evaluation metrics.
Conclusion
Accurate volume forecasting is a critical component of optimizing execution algorithms, directly influencing their ability to minimize market impact and improve trading efficiency. While no single model can perfectly predict minute-by-minute volume distributions, this research demonstrates that a hybrid approach—leveraging market microstructure knowledge alongside machine learning techniques—can provide significant improvement in volume estimation.
By classifying stocks into distinct liquidity-based groups, we balance precision and stability, ensuring that Highly Liquid Stocks benefit from stock-specific profiles while Moderately Liquid Stocks leverage robust clustering techniques.
Low Liquidity stocks, due to their erratic trading behavior and lack of reliable volume structure, pose the greatest challenge no matter how a volume profile is to be estimated. For these stocks, rather than attempting to generate precise minute-by-minute volume distributions, we employ broader approximations that capture general liquidity trends while minimizing the risk of overfitting to noisy or inconsistent data.
Overall, the framework outlined in this paper demonstrates strong consistency out-of-sample, reinforcing its applicability across different market conditions. It offers a scalable and adaptable solution for volume prediction, enhancing the execution quality of trading algorithms.
Appendix
In this appendix, we analyze the intraday trading volume patterns across stock clusters as described in the Moderately Liquid Stocks group defined in the text above, focusing on the first and last hours of the US equity trading session.
Key observations include:
- Volume Concentration around Market Open & Close: Stocks exhibit distinct volume profiles, with clusters varying in their front-loaded (early session) and back-loaded (late session) tendencies.
- Cluster-Specific Behaviors: We highlight differences in spread, liquidity, and trading activity, revealing how stocks group based on their intraday volume dynamics.
- Notable Trends: A consistent mid-morning volume spike (~10 AM) suggests a stabilization period after initial volatility, while heightened activity near the close reflects positioning for the market’s end.
This appendix provides supporting data, including cluster distributions (Tables 4-6 & Figure 12), to quantify these patterns and offer deeper insights into the market microstructure of clustered stocks. This analysis complements our broader findings on equity trading behaviors.
Early- & Late-Day Volume Patterns
US equities are well-known to have a common increase in trading early in the day and later in the day; careful evaluation of the behavior during those time periods for clustered stocks is an important step. As shown in Figure 8 below, we find that cluster 0 is the least front-loaded (lowest volume fraction in the first 10 minutes) while cluster 6 is the most front-loaded.

Figure 8: Intraday volume in the first hour of continuous trading (1-min bins).

Figure 9: Intraday volume in the last hour of continuous trading (1-min bins).
We observe the most significant variations in the volume curve across different clusters during the first and last 10 minutes of the trading day. These periods are often characterized by heightened market activity as investors react to overnight news and prepare for the closing session. Additionally, in Figure 8 we observe a noticeable volume peak in all clusters around 10am ET. This spike could be attributed to investors making more decisive moves after the initial market volatility subsides following the opening. By 10am ET, the market generally reaches a more stable state, offering a clearer picture of market sentiment for the day, which prompts more active trading and repositioning. Similarly, in Figure 9, towards market close, we observe increased volume approaching the closing auction. Cluster 0 was least front-loaded and is most back-loaded as a result.
To further understand the behavior of each cluster, we dive deeper into their formation. This analysis involves examining key descriptive statistics and identifying distinguishing characteristics for each cluster. We also look at the distribution of stocks across these clusters (Table 4), paying particular attention to the percentage of stocks in each cluster that fall within specific ranges for average spread and volume (Tables 5 and 6, Figure 10). The following tables and figure allow us to better characterize how each cluster is defined by these important metrics and the underlying dynamics and trading behavior of their corresponding member stocks.

Table 4: Count of cluster member stocks.

Table 5: Spread distribution of cluster member stocks.

Table 6: Liquidity distributions of cluster member stocks.

Figure 10: Visual depiction of cluster membership in accordance with volume (horizontal axis, in log scale) and spread (vertical axis, in log scale) distributions.
At BestEx Research, we care how you fill. We know from experience that systematic, quantitative decision-making around algorithm design contributes to globally optimal execution and results in significantly reduced execution costs.
Reach out to us with questions at research@bestexresearch.com or learn more about us at bestexresearch.com.
This research paper reflects the views and opinions of BestEx Research Group LLC. It does not constitute legal, tax, investment, financial, or other professional advice. Nothing contained herein constitutes a solicitation, recommendation, endorsement, or offer to buy or sell securities, futures, or other financial instruments or to engage in financial strategies which may include algorithms. This material may not be a comprehensive or complete statement of the matters discussed herein. Nothing in this paper is a guarantee or assurance that any particular algorithmic solution fits you, or that you will benefit from it. You should consider whether our research is suitable for your particular circumstances and needs and, if appropriate, seek professional advice.
Let us show you what's possible
Execution engineered to preserve your returns
